The writing is on the wall for the NHS.
The writing is on the wall for the NHS.
It is called the Francis Report and there is a lot of it. Just the 290 recommendations runs to 30 pages. It would need a very big wall and very small writing to put it all up there for all to see.
So predictably the speed-readers have latched onto specific words – such as “Inspectors“.
Recommendation 137 “Inspection should remain the central method for monitoring compliance with fundamental standards.”
And it goes further by recommending “A specialist cadre of hospital inspectors should be established …”
A predictable wail of anguish rose from the ranks “Not more inspectors! The last lot did not do much good!”
The word “cadre” is not one that is used in common parlance so I looked it up:
Cadre: 1. a core group of people at the center of an organization, especially military; 2. a small group of highly trained people, often part of a political movement.
So it has a military, centralist, specialist, political flavour. No wonder there was a wail of anguish! Perhaps this “cadre of inspectors” has been unconsciously labelled with another name? Persecutors.
Of more interest is the “highly trained” phrase. Trained to do what? Trained by whom? Clearly none of the existing schools of NHS management who have allowed the fiasco to happen in the first place. So who – exactly? Are these inspectors intended to be protectors, persecutors, or educators?
And what would they inspect?
And how would they use the output of such an inspection?
Would the fear of the inspection and its possible unpleasant consequences be the stick to motivate compliance?
Is the language of the Francis Report going to create another brick wall of resistance from the rubble of the ruins of the reputation of the NHS? Many self-appointed experts are already saying that implementing 290 recommendations is impossible.
They are incorrect.
The number of recommendations is a measure of the breadth and depth of the rot. So the critical-to-success factor is to implement them in a well-designed order. Get the first few in place and working and the rest will follow naturally. Get the order wrong and the radical cure will kill the patient.
So where do we start?
Let us look at the inspection question again. Why would we fear an external inspection? What are we resisting? There are three facets to this: first we do not know what is expected of us; second we do not know if we can satisfy the expectation; and third we fear being persecuted for failing to achieve the impossible.
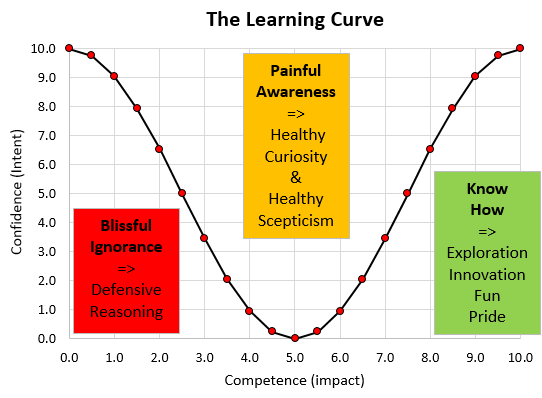
W Edwards Deming used a very effective demonstration of the dangers of well-intended but badly-implemented quality improvement by inspection: it was called the Red Bead Game. The purpose of the game was to illustrate how to design an inspection system that actually helps to achieve the intended goal. Sustained improvement.
This is applied Improvement Science and I will illustrate how it is done with a real and current example.
I am assisting a department in a large NHS hospital to improve the quality of their service. I have been sent in as an external inspector. The specific quality metric they have been tasked to improve is the turnaround time of the specialist work that they do. This is a flow metric because a patient cannot leave hospital until this work is complete – and more importantly it is a flow and quality metric because when the hospital is full then another patient, one who urgently needs to be admitted, will be waiting for the bed to be vacated. One in one out.
The department have been set a standard to meet, a target, a specification, a goal. It is very clear and it is easily measurable. They have to turnaround each job of work in less than 2 hours. This is called a lead time specification and it is arbitrary. But it is not unreasonable from the perspective of the patient waiting to leave and for the patient waiting to be admitted. Neither want to wait.
The department has a sophisticated IT system that measures their performance. They use it to record when each job starts and when each job is finished and from those two events the software calculates the lead time for each job in real-time. At the end of each day the IT system counts how many jobs were completed in less than 2 hours and compares this with how many were done in total and calculates a ratio which it presents as a percentage in the range of 0 and 100. This is called the process yield. The department are dedicated and they work hard and they do all the work that arrives each day the same day – no matter how long it takes. And at the end of each day they have their score for that day. And it is almost never 100%. Not never. Almost never. But it is not good enough and they are being blamed for it. In turn they blame others for making their job more difficult. It is a blame-game and it has been going on for years.
So how does an experienced Improvement Science-trained Inspector approach this sort of “wicked” problem?
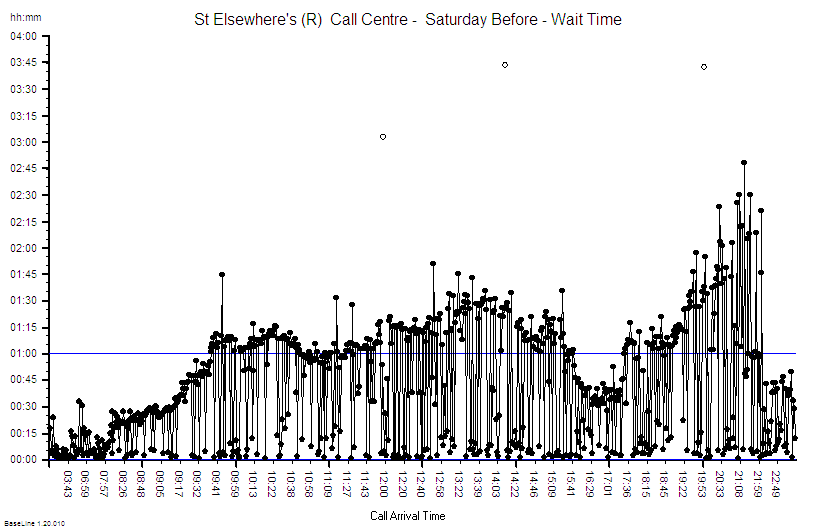
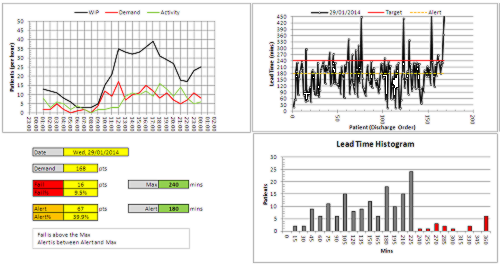
First we need to get the writing on the wall – we need to see the reality – we need to “plot the dots” – we need to see what the performance is doing over time – we need to see the voice of the process. And that requires only their data, a pencil, some paper and for the chart to be put on the on the wall where everyone can see it.
 This is what their daily % yield data for three consecutive weeks looked like as a time-series chart. The thin blue line is the 100% yield target.
This is what their daily % yield data for three consecutive weeks looked like as a time-series chart. The thin blue line is the 100% yield target.
The 100% target was only achieved on three days – and they were all Sundays. On the other Sunday it was zero (which may mean that there was no data to calculate a ratio from).
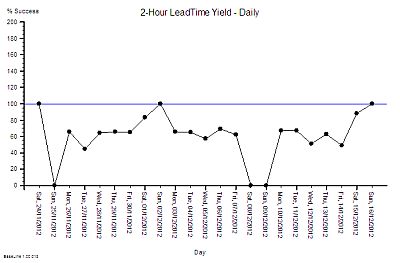
There is wide variation from one day to the next and it is the variation as well as the average that is of interest to an improvement scientist. What is the source of the variation it? If 100% yield can be achieved some days then what is different about those days?
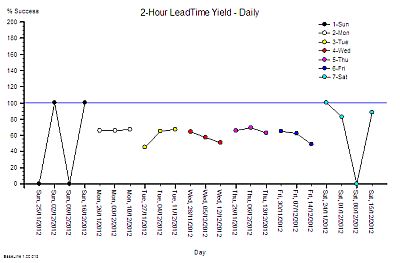
So our Improvement science-trained Inspector will now re-plot the data in a different way – as rational groups. This exposes the issue clearly. The variation on Weekends is very wide and the performance during the Weekdays is much less variable. What this says is that the weekend system and the weekday system are different. This means that it is invalid to combine the data for both.
It also raises the question of why there is such high variation in yield only at weekends? The chart cannot answer the question, so our IS-trained Inspector digs a bit deeper and discovers that the volume of work done at the weekend is low, the staffing of the department is different, and that the recording of the events is less reliable. In short – we cannot even trust the weekend data – so we have two reasons to justify excluding it from our chart and just focusing on what happens during the week.
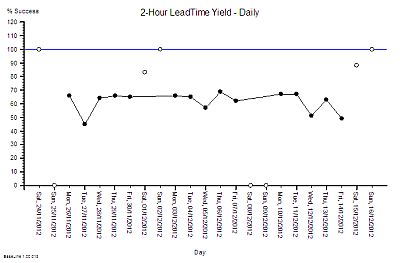 We re-plot our chart, marking the excluded weekend data as not for analysis.
We re-plot our chart, marking the excluded weekend data as not for analysis.
We can now see that the weekday performance of our system is visible, less variable, and the average is a long way from 100%.
The team are working hard and still only achieving mediocre performance. That must mean that they need something that is missing. Motivating maybe. More people maybe. More technology maybe. But there is no more money for more people or technology and traditional JFDI motivation does not seem to have helped.
This looks like an impossible task!
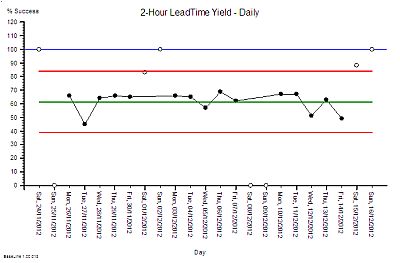
So what does our Inspector do now? Mark their paper with a FAIL and put them on the “To Be Sacked for Failing to Meet an Externally Imposed Standard“ heap?
Nope.
Our IS-trained Inspector calculates the limits of expected performance from the data and plots these limits on the chart – the red lines. The computation is not difficult – it can be done with a calculator and the appropriate formula. It does not need a sophisticated IT system.
What this chart now says is “The current design of this process is capable of delivering between 40% and 85% yield. To expect it do do better is unrealistic”. The implication for action is “If we want 100% yield then the process needs to be re-designed.” Persecution will not work. Blame will not work. Hoping-for-the-best will not work. The process must be redesigned.
Our improvement scientist then takes off the Inspector’s hat and dons the Designer’s overalls and gets to work. There is a method to this and it is called 6M Design®.

First we need to have a way of knowing if any future design changes have a statistically significant impact – for better or for worse. To do this the chart is extended into the future and the red lines are projected forwards in time as the black lines called locked-limits. The new data is compared with this projected baseline as it comes in. The weekends and bank holidays are excluded because we know that they are a different system. On one day (20/12/2012) the yield was surprisingly high. Not 100% but more than the expected upper limit of 85%.
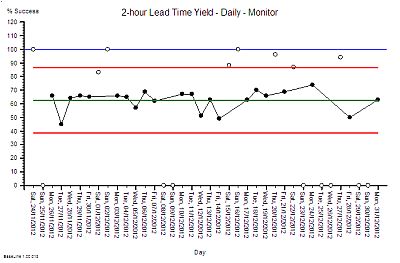 The alerts us to investigate and we found that it was a ‘hospital bed crisis’ and an ‘all hands to the pumps’ distress call went out.
The alerts us to investigate and we found that it was a ‘hospital bed crisis’ and an ‘all hands to the pumps’ distress call went out.
Extra capacity was pulled to the process and less urgent work was delayed until later. It is the habitual reaction-to-a-crisis behaviour called “expediting” or “firefighting”. So after the crisis had waned and the excitement diminished the performance returned to the expected range. A week later the chart signals us again and we investigate but this time the cause was different. It was an unusually quiet day and there was more than enough hands on the pumps.
Both of these days are atypically good and we have an explanation for each of them. This is called an assignable cause. So we are justified in excluding these points from our measure of the typical baseline capability of our process – the performance the current design can be expected to deliver.
An inexperienced manager might conclude from these lessons that what is needed is more capacity. That sounds and feels intuitively obvious and it is correct that adding more capacity may improve the yield – but that does not prove that lack of capacity is the primary cause. There are many other causes of long lead times just as there are many causes of headaches other than brain tumours! So before we can decide the best treatment for our under-performing design we need to establish the design diagnosis. And that is done by inspecting the process in detail. And we need to know what we are looking for; the errors of design commission and the errors of design omission. The design flaws.
Only a trained and experienced process designer can spot the flaws in a process design. Intuition will trick the untrained and inexperienced.
Once the design diagnosis is established then the redesign stage can commence. Design always works to a specification and in this case it was clear – to significantly improve the yield to over 90% at no cost. In other words without needing more people, more skills, more equipment, more space, more anything. The design assignment was made trickier by the fact that the department claimed that it was impossible to achieve significant improvement without adding extra capacity. That is why the Inspector had been sent in. To evaluate that claim.
The design inspection revealed a complex adaptive system – not a linear, deterministic, production-line that manufactures widgets. The department had to cope with wide variation in demand, wide variation in quality of request, wide variation in job complexity, and wide variation in urgency – all at the same time. But that is the nature of healthcare and acute hospital work. That is the expected context.
The analysis of the current design revealed that it was not well suited for this requirement – and the low yield was entirely predictable. The analysis also revealed that the root cause of the low yield was not lack of either flow-capacity or space-capacity.
This insight led to the suggestion that it would be possible to improve yield without increasing cost. The department were polite but they did not believe it was possible. They had never seen it, so why should they be expected to just accept this on faith?
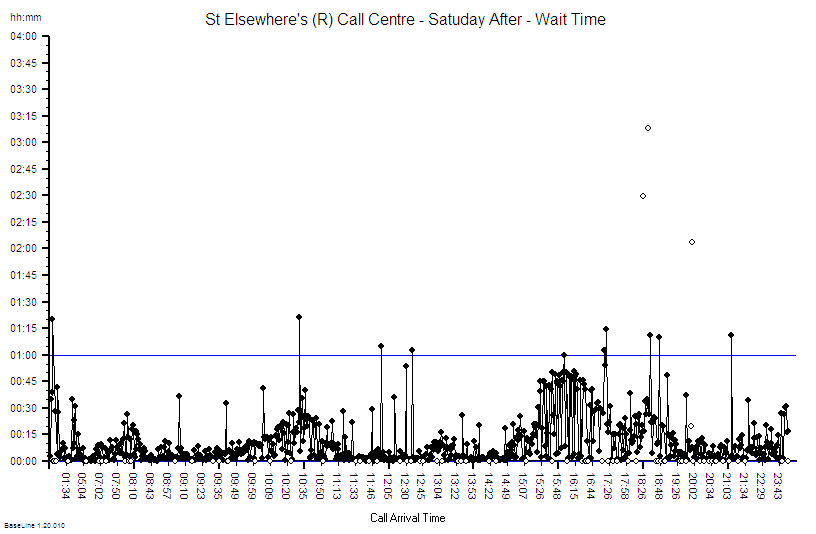
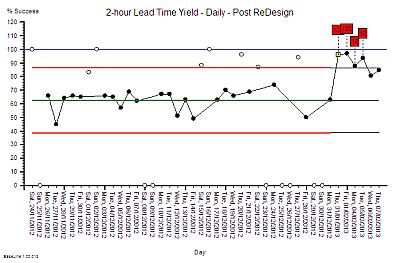 So, the next step was to develop, test and demonstrate a new design and that was done in three stages. The final stage was the Reality Test – the actual process design was changed for just one day – and the yield measured and compared with the predicted improvement.
So, the next step was to develop, test and demonstrate a new design and that was done in three stages. The final stage was the Reality Test – the actual process design was changed for just one day – and the yield measured and compared with the predicted improvement.
This was the validity test – the proof of the design pudding. And to visualise the impact we used the same technique as before – extending the baseline of our time-series chart, locking the limits, and comparing the “after” with the “before”.
The yellow point marks the day of the design test. The measured yield was well above the upper limit which suggested that the design change had made a significant improvement. A statistically significant improvement. There was no more capacity than usual and the day was not unusually quiet. At the end of the day we held a team huddle.
Our first question was “How did the new design feel?” The consensus was “Calmer, smoother, fewer interruptions” and best of all “We finished on time – there was no frantic catch up at the end of the day and no one had to stay late to complete the days work!”
The next question was “Do we want to continue tomorrow with this new design or revert back to the old one?” The answer was clear “Keep going with the new design. It feels better.”
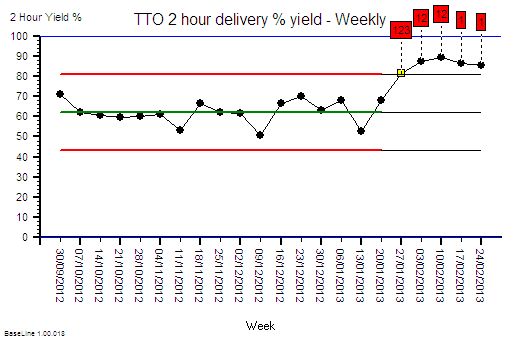
The same chart was used to show what happened over the next few days – excluding the weekends as before. The improvement was sustained – it did not revert to the original because the process design had been changed. Same work, same capacity, different process – higher yield. The red flags on the charts mark the statistically significant evidence of change and the cluster of red flags is very strong statistical evidence that the improvement is not due to chance.
The next phase of the 6M Design® method is to continue to monitor the new process to establish the new baseline of expectation. That will require at least twelve data points and it is in progress. But we have enough evidence of a significant improvement. This means that we have no credible justification to return to the old design, and it also implies that it is no longer valid to compare the new data against the old projected limits. Our chart tells us that we need to split the data into before-and-after and to calculate new averages and limits for each segment separately. We have changed the voice of the process by changing the design.
 And when we split the data at the point-of-change then the red flags disappear – which means that our new design is stable. And it has a new capability – a better one. We have moved closer to our goal of 100% yield. It is still early days and we do not really have enough data to calculate the new capability.
And when we split the data at the point-of-change then the red flags disappear – which means that our new design is stable. And it has a new capability – a better one. We have moved closer to our goal of 100% yield. It is still early days and we do not really have enough data to calculate the new capability.
What we can say is that we have improved average quality yield from 63% to about 90% at no cost using a sequence of process diagnose, design, deliver. Study-Plan-Do.
And we have hard evidence that disproves the impossibility hypothesis.
And that was the goal of the first design change – it was not to achieve 100% yield in one jump. Our design simulation had predicted an improvement to about 90%. And there are other design changes to follow that need this stable foundation to build on. The order of implementation is critical – and each change needs time to bed in before the next change is made. That is the nature of the challenge of improving a complex adaptive system.
The cost to the department was zero but the benefit was huge. The bigger benefit to the organisation was felt elsewhere – the ‘customers’ saw a higher quality, quicker process – and there will be a financial benefit for the whole system. It will be difficult to measure with our current financial monitoring systems but it will be real and it will be there – lurking in the data.
The improvement required a trained and experienced Inspector/Designer/Educator to start the wheel of change turning. There are not many of these in the NHS – but the good news is that the first level of this training is now available.
What this means for the post-Francis Report II NHS is that those who want to can choose to leap over the wall of resistance that is being erected by the massing legions of noisy cynics. It means we can all become our own inspectors. It means we can all become our own improvers. It means we can all learn to redesign our systems so that they deliver higher safety, better quality, more quickly and at no extra one-off or recurring cost. We all can have nothing to fear from the Specialist Cadre of Hospital Inspectors.
The writing is on the wall.
15/02/2013 – Two weeks in and still going strong. The yield has improved from 63% to 92% and is stable. Improvement-by-design works.
10/03/2013 – Six weeks in and a good time to test if the improvement has been sustained.
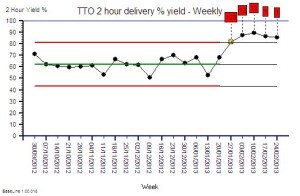 The chart is the weekly performance plotted for 17 weeks before the change and for 5 weeks after. The advantage of weekly aggregated data is that it removes the weekend/weekday 7-day cycle and reduces the effect of day-to-day variation.
The chart is the weekly performance plotted for 17 weeks before the change and for 5 weeks after. The advantage of weekly aggregated data is that it removes the weekend/weekday 7-day cycle and reduces the effect of day-to-day variation.
The improvement is obvious, significant and has been sustained. This is the objective improvement. More important is the subjective improvement.
Here is what Chris M (departmental operational manager) wrote in an email this week (quoted with permission):
Hi Simon
It is I who need to thank you for explaining to me how to turn our pharmacy performance around and ultimately improve the day to day work for the pharmacy team (and the trust staff). This will increase job satisfaction and make pharmacy a worthwhile career again instead of working in constant pressure with a lack of achievement that had made the team feel rather disheartened and depressed. I feel we can now move onwards and upwards so thanks for the confidence boost.
Best wishes and many thanks
Chris
This is what Improvement Science is all about!

















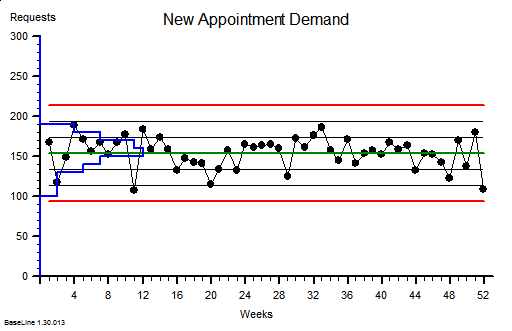
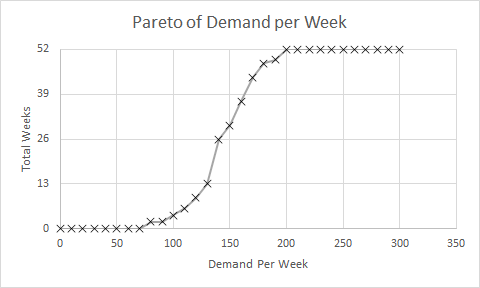






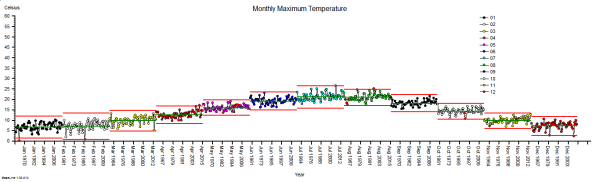
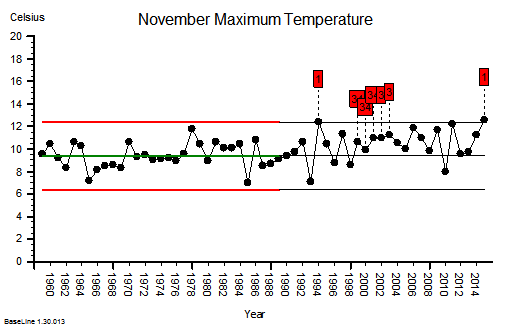
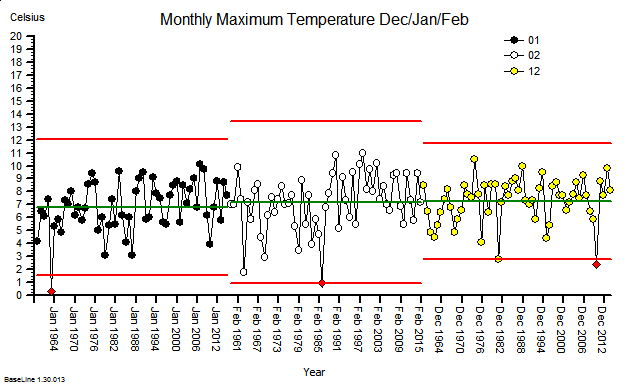 These were indeed almost identical so I lumped them together as a ‘winter’ group and compared the earlier half with the later half using another BaseLine© feature called segmentation.
These were indeed almost identical so I lumped them together as a ‘winter’ group and compared the earlier half with the later half using another BaseLine© feature called segmentation.