There is a common system ailment which every Improvement Scientist needs to know how to manage.
There is a common system ailment which every Improvement Scientist needs to know how to manage.
In fact, it is probably the commonest.
The Symptoms: Disappointingly long waiting times and all resources running flat out.
The Diagnosis? 90%+ of managers say “It is obvious – lack of capacity!”.
The Treatment? 90%+ of managers say “It is obvious – more capacity!!”
Intuitively obvious maybe – but unfortunately these are incorrect answers. Which implies that 90%+ of managers do not understand how their systems work. That is a bit of a worry. Lament not though – misunderstanding is a treatable symptom of an endemic system disease called agnosia (=not knowing).
The correct answer is “I do not yet have enough information to make a diagnosis“.
This answer is more helpful than it looks because it prompts four other questions:
Q1. “What other possible system diagnoses are there that could cause this pattern of symptoms?”
Q2. “What do I need to know to distinguish these system diagnoses?”
Q3. “How would I treat the different ones?”
Q4. “What is the risk of making the wrong system diagnosis and applying the wrong treatment?”
Before we start on this list we need to set out a few ground rules that will protect us from more intuitive errors (see last week).
The first Rule is this:
Rule #1: Data without context is meaningless.
For example 130 is a number – it is data. 130 what? 130 mmHg. Ah ha! The “mmHg” is the units – it means millimetres of mercury and it tells us this data is a pressure. But what, where, when,who, how and why? We need more context.
“The systolic blood pressure measured in the left arm of Joe Bloggs, a 52 year old male, using an Omron M2 oscillometric manometer on Saturday 20th October 2012 at 09:00 is 130 mmHg”.
The extra context makes the data much more informative. The data has become information.
To understand what the information actually means requires some prior knowledge. We need to know what “systolic” means and what an “oscillometric manometer” is and the relevance of the “52 year old male”. This ability to extract meaning from information has two parts – the ability to recognise the language – the syntax; and the ability to understand the concepts that the words are just labels for; the semantics.
To use this deeper understanding to make a wise decision to do something (or not) requires something else. Exploring that would distract us from our current purpose. The point is made.
Rule #1: Data without context is meaningless.
In fact it is worse than meaningless – it is dangerous. And it is dangerous because when the context is missing we rarely stop and ask for it – we rush ahead and fill the context gaps with assumptions. We fill the context gaps with beliefs, prejudices, gossip, intuitive leaps, and sometimes even plain guesses.
This is dangerous – because the same data in a different context may have a completely different meaning.
To illustrate. If we change one word in the context – if we change “systolic” to “diastolic” then the whole meaning changes from one of likely normality that probably needs no action; to one of serious abnormality that definitely does. If we missed that critical word out then we are in danger of assuming that the data is systolic blood pressure – because that is the most likely given the number. And we run the risk of missing a common, potentially fatal and completely treatable disease called Stage 2 hypertension.
There is a second rule that we must always apply when using data from systems. It is this:
Rule #2: Plot time-series data as a chart – a system behaviour chart (SBC).
The reason for the second rule is because the first question we always ask about any system must be “Is our system stable?”
Q: What do we mean by the word “stable”? What is the concept that this word is a label for?
A: Stable means predictable-within-limits.
Q: What limits?
A: The limits of natural variation over time.
Q: What does that mean?
A: Let me show you.
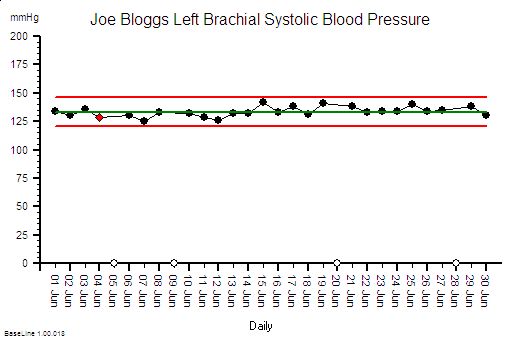
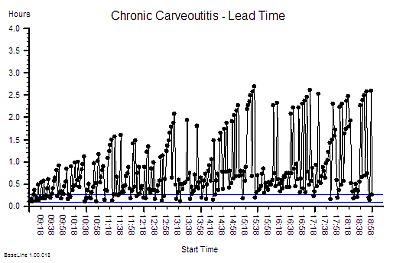
Joe Bloggs is disciplined. He measures his blood pressure almost every day and he plots the data on a chart together with some context . The chart shows that his systolic blood pressure is stable. That does not mean that it is constant – it does vary from day to day. But over time a pattern emerges from which Joe Bloggs can see that, based on past behaviour, there is a range within which future behaviour is predicted to fall. And Joe Bloggs has drawn these limits on his chart as two red lines and he has called them expectation lines. These are the limits of natural variation over time of his systolic blood pressure.
If one day he measured his blood pressure and it fell outside that expectation range then he would say “I didn’t expect that!” and he could investigate further. Perhaps he made an error in the measurement? Perhaps something else has changed that could explain the unexpected result. Perhaps it is higher than expected because he is under a lot of emotional stress a work? Perhaps it is lower than expected because he is relaxing on holiday?
His chart does not tell him the cause – it just flags when to ask more “What might have caused that?” questions.
If you arrive at a hospital in an ambulance as an emergency then the first two questions the emergency care team will need to know the answer to are “How sick are you?” and “How stable are you?”. If you are sick and getting sicker then the first task is to stabilise you, and that process is called resuscitation. There is no time to waste.
So how is all this relevant to the common pattern of symptoms from our sick system: disappointingly long waiting times and resources running flat out?
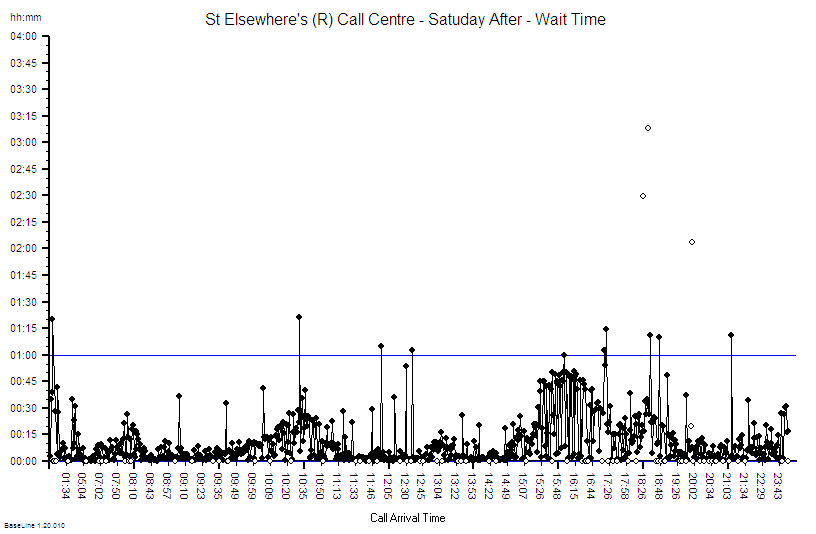
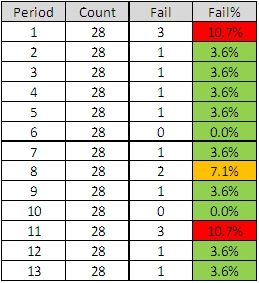
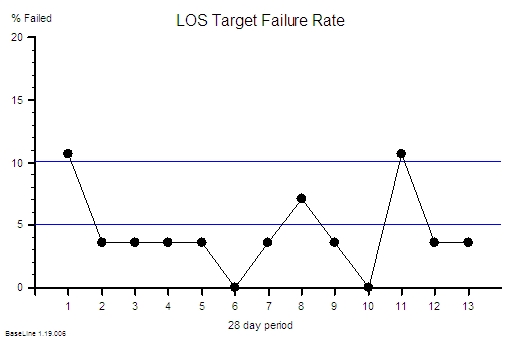
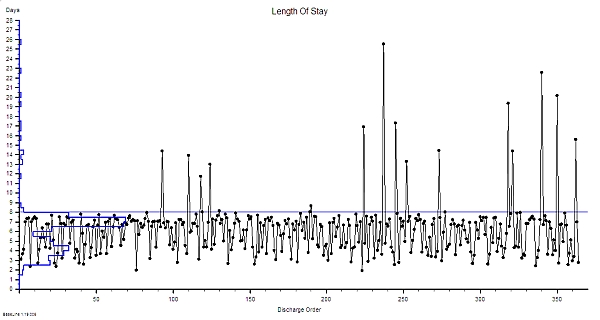
Using Rule#1 and Rule#2: To start to establish the diagnosis we need to add the context to the data and then plot our waiting time information as a time series chart and ask the “Is our system stable?” question.
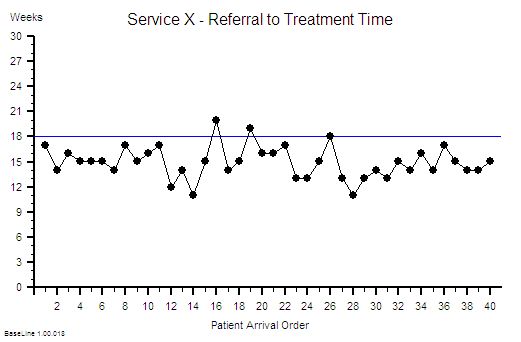
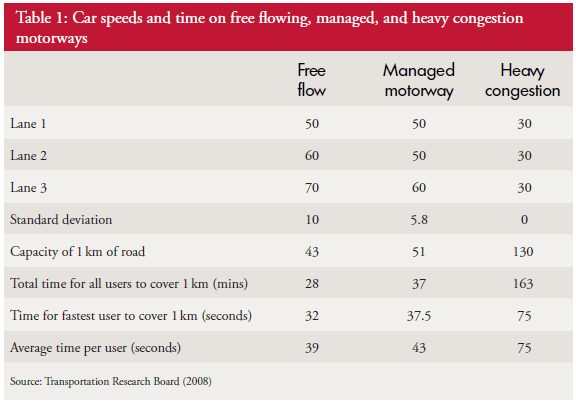
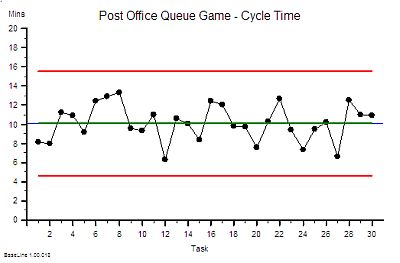
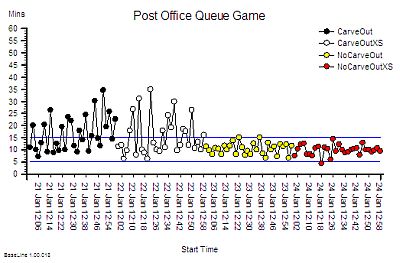
Suppose we do that and this is what we see. The context is that we are measuring the Referral-to-Treatment Time (RTT) for consecutive patients referred to a single service called X. We only know the actual RTT when the treatment happens and we want to be able to set the expectation for new patients when they are referred – because we know that if patients know what to expect then they are less likely to be disappointed – so we plot our retrospective RTT information in the order of referral. With the Mark I Eyeball Test (i.e. look at the chart) we form the subjective impression that our system is stable. It is delivering a predictable-within-limits RTT with an average of about 15 weeks and an expected range of about 10 to 20 weeks.
So far so good.
Unfortunately, the purchaser of our service has set a maximum limit for RTT of 18 weeks – a key performance indicator (KPI) target – and they have decided to “motivate” us by withholding payment for every patient that we do not deliver on time. We can now see from our chart that failures to meet the RTT target are expected, so to avoid the inevitable loss of income we have to come up with an improvement plan. Our jobs will depend on it!
Now we have a problem – because when we look at the resources that are delivering the service they are running flat out – 100% utilisation. They have no spare flow-capacity to do the extra work needed to reduce the waiting list. Efficiency drives and exhortation have got us this far but cannot take us any further. We conclude that our only option is “more capacity”. But we cannot afford it because we are operating very close to the edge. We are a not-for-profit organisation. The budgets are tight as a tick. Every penny is being spent. So spending more here will mean spending less somewhere else. And that will cause a big argument.
So the only obvious option left to us is to change the system – and the easiest thing to do is to monitor the waiting time closely on a patient-by-patient basis and if any patient starts to get close to the RTT Target then we bump them up the list so that they get priority. Obvious!
WARNING: We are now treating the symptoms before we have diagnosed the underlying disease!
 In medicine that is a dangerous strategy. Symptoms are often not-specific. Different diseases can cause the same symptoms. An early morning headache can be caused by a hangover after a long night on the town – it can also (much less commonly) be caused by a brain tumour. The risks are different and the treatment is different. Get that diagnosis wrong and disappointment will follow. Do I need a hole in the head or will a paracetamol be enough?
In medicine that is a dangerous strategy. Symptoms are often not-specific. Different diseases can cause the same symptoms. An early morning headache can be caused by a hangover after a long night on the town – it can also (much less commonly) be caused by a brain tumour. The risks are different and the treatment is different. Get that diagnosis wrong and disappointment will follow. Do I need a hole in the head or will a paracetamol be enough?
Back to our list of questions.
What else can cause the same pattern of symptoms of a stable and disappointingly long waiting time and resources running at 100% utilisation?
There are several other process diseases that cause this symptom pattern and none of them are caused by lack of capacity.
Which is annoying because it challenges our assumption that this pattern is always caused by lack of capacity. Yes – that can sometimes be the cause – but not always.
But before we explore what these other system diseases are we need to understand why our current belief is so entrenched.
One reason is because we have learned, from experience, that if we throw flow-capacity at the problem then the waiting time will come down. When we do “waiting list initiatives” for example. So if adding flow-capacity reduces the waiting time then the cause must be lack of capacity? Intuitively obvious.
Intuitively obvious it may be – but incorrect too. We have been tricked again. This is flawed causal logic. It is called the illusion of causality.
To illustrate. If a patient complains of a headache and we give them paracetamol then the headache will usually get better. That does not mean that the cause of headaches is a paracetamol deficiency. The headache could be caused by lots of things and the response to treatment does not reliably tell us which possible cause is the actual cause. And by suppressing the symptoms we run the risk of missing the actual diagnosis while at the same time deluding ourselves that we are doing a good job.
If a system complains of long waiting times and we add flow-capacity then the long waiting time will usually get better. That does not mean that the cause of long waiting time is lack of flow-capacity. The long waiting time could be caused by lots of things. The response to treatment does not reliably tell us which possible cause is the actual cause – so by suppressing the symptoms we run the risk of missing the diagnosis while at the same time deluding ourselves that we are doing a good job.
The similarity is not a co-incidence. All systems behave in similar ways. Similar counter-intuitive ways.
So what other system diseases can cause a stable and disappointingly long waiting time and high resource utilisation?
 The commonest system disease that is associated with these symptoms is a time trap – and they have nothing to do with capacity or flow.
The commonest system disease that is associated with these symptoms is a time trap – and they have nothing to do with capacity or flow.
They are part of the operational policy design of the system. And we actually design time traps into our systems deliberately! Oops!
We create a time trap when we deliberately delay doing something that we could do immediately – perhaps to give the impression that we are very busy or even overworked! We create a time trap whenever we deferring until later something we could do today.
If the task does not seem important or urgent for us then it is a candidate for delaying with a time trap.
Unfortunately it may be very important and urgent for someone else – and a delay could be expensive for them.
Creating time traps gives us a sense of power – and it is for that reason they are much loved by bureaucrats.
To illustrate how time traps cause these symptoms consider the following scenario:
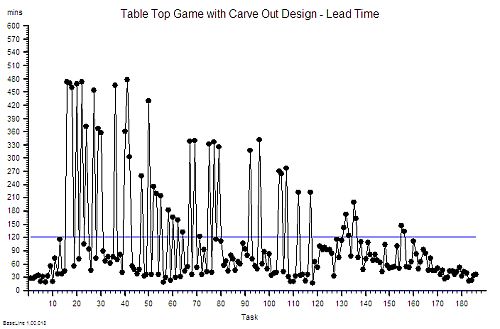
Suppose I have just enough resource-capacity to keep up with demand and flow is smooth and fault-free. My resources are 100% utilised; the flow-in equals the flow-out; and my waiting time is stable. If I then add a time trap to my design then the waiting time will increase but over the long term nothing else will change: the flow-in, the flow-out, the resource-capacity, the cost and the utilisation of the resources will all remain stable. I have increased waiting time without adding or removing capacity. So lack of resource-capacity is not always the cause of a longer waiting time.
This new insight creates a new problem; a BIG problem.
Suppose we are measuring flow-in (demand) and flow-out (activity) and time from-start-to-finish (lead time) and the resource usage (utilisation) and we are obeying Rule#1 and Rule#2 and plotting our data with its context as system behaviour charts. If we have a time trap in our system then none of these charts will tell us that a time-trap is the cause of a longer-than-necessary lead time.
Aw Shucks!
And that is the primary reason why most systems are infested with time traps. The commonly reported performance metrics we use do not tell us that they are there. We cannot improve what we cannot see.
Well actually the system behaviour charts do hold the clues we need – but we need to understand how systems work in order to know how to use the charts to make the time trap diagnosis.
Q: Why bother though?
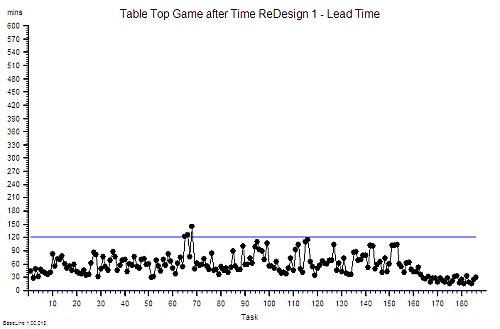
A: Simple. It costs nothing to remove a time trap. We just design it out of the process. Our flow-in will stay the same; our flow-out will stay the same; the capacity we need will stay the same; the cost will stay the same; the revenue will stay the same but the lead-time will fall.
Q: So how does that help me reduce my costs? That is what I’m being nailed to the floor with as well!
A: If a second process requires the output of the process that has a hidden time trap then the cost of the queue in the second process is the indirect cost of the time trap. This is why time traps are such a fertile cause of excess cost – because they are hidden and because their impact is felt in a different part of the system – and usually in a different budget.
 To illustrate. Suppose that 60 patients per day are discharged from our hospital and each one requires a prescription of to-take-out (TTO) medications to be completed before they can leave. Suppose that there is a time trap in this drug dispensing and delivery process. The time trap is a policy where a porter is scheduled to collect and distribute all the prescriptions at 5 pm. The porter is busy for the whole day and this policy ensures that all the prescriptions for the day are ready before the porter arrives at 5 pm. Suppose we get the event data from our electronic prescribing system (EPS) and we plot it as a system behaviour chart and it shows most of the sixty prescriptions are generated over a four hour period between 11 am and 3 pm. These prescriptions are delivered on paper (by our busy porter) and the pharmacy guarantees to complete each one within two hours of receipt although most take less than 30 minutes to complete. What is the cost of this one-delivery-per-day-porter-policy time trap? Suppose our hospital has 500 beds and the total annual expense is £182 million – that is £0.5 million per day. So sixty patients are waiting for between 2 and 5 hours longer than necessary, because of the porter-policy-time-trap, and this adds up to about 5 bed-days per day – that is the cost of 5 beds – 1% of the total cost – about £1.8 million. So the time trap is, indirectly, costing us the equivalent of £1.8 million per annum. It would be much more cost-effective for the system to have a dedicated porter working from 12 am to 5 pm doing nothing else but delivering dispensed TTOs as soon as they are ready! And assuming that there are no other time traps in the decision-to-discharge process; such as the time trap created by batching all the TTO prescriptions to the end of the morning ward round; and the time trap created by the batch of delivered TTOs waiting for the nurses to distribute them to the queue of waiting patients!
To illustrate. Suppose that 60 patients per day are discharged from our hospital and each one requires a prescription of to-take-out (TTO) medications to be completed before they can leave. Suppose that there is a time trap in this drug dispensing and delivery process. The time trap is a policy where a porter is scheduled to collect and distribute all the prescriptions at 5 pm. The porter is busy for the whole day and this policy ensures that all the prescriptions for the day are ready before the porter arrives at 5 pm. Suppose we get the event data from our electronic prescribing system (EPS) and we plot it as a system behaviour chart and it shows most of the sixty prescriptions are generated over a four hour period between 11 am and 3 pm. These prescriptions are delivered on paper (by our busy porter) and the pharmacy guarantees to complete each one within two hours of receipt although most take less than 30 minutes to complete. What is the cost of this one-delivery-per-day-porter-policy time trap? Suppose our hospital has 500 beds and the total annual expense is £182 million – that is £0.5 million per day. So sixty patients are waiting for between 2 and 5 hours longer than necessary, because of the porter-policy-time-trap, and this adds up to about 5 bed-days per day – that is the cost of 5 beds – 1% of the total cost – about £1.8 million. So the time trap is, indirectly, costing us the equivalent of £1.8 million per annum. It would be much more cost-effective for the system to have a dedicated porter working from 12 am to 5 pm doing nothing else but delivering dispensed TTOs as soon as they are ready! And assuming that there are no other time traps in the decision-to-discharge process; such as the time trap created by batching all the TTO prescriptions to the end of the morning ward round; and the time trap created by the batch of delivered TTOs waiting for the nurses to distribute them to the queue of waiting patients!
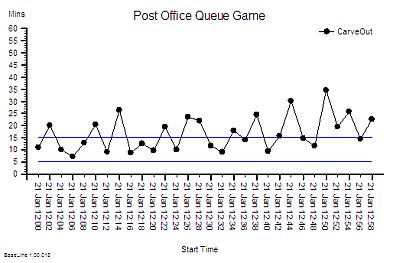
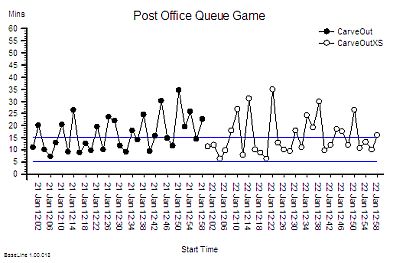
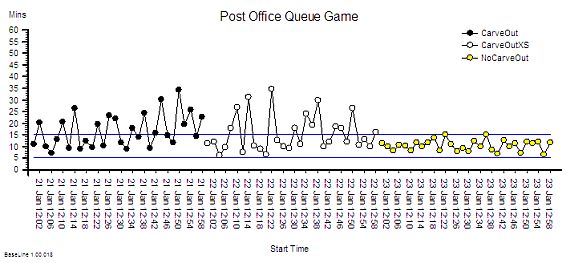
Q: So how do we nail the diagnosis of a time trap and how do we differentiate it from a Batch or a Bottleneck or Carveout?
A: To learn how to do that will require a bit more explanation of the physics of processes.
And anyway if I just told you the answer you would know how but might not understand why it is the answer. Knowledge and understanding are not the same thing. Wise decisions do not follow from just knowledge – they require understanding. Especially when trying to make wise decisions in unfamiliar scenarios.
It is said that if we are shown we will understand 10%; if we can do we will understand 50%; and if we are able to teach then we will understand 90%.
So instead of showing how instead I will offer a hint. The first step of the path to knowing how and understanding why is in the following essay:
A Study of the Relative Value of Different Time-series Charts for Proactive Process Monitoring. JOIS 2012;3:1-18
Click here to visit JOIS