
 Fire-fighting is a behaviour that has a long history, and before Fireman Sam arrived on the scene we had the Bucket Brigade. This was a people-intensive process designed to deliver water from the nearest pump, pond or river with as little risk, delay and effort as possible. The principle of a bucket-brigade is that a chain of people forms between the pump and the fire and they pass buckets in two directions – full ones from the pump to the fire and empty ones from the fire back to the pump.
Fire-fighting is a behaviour that has a long history, and before Fireman Sam arrived on the scene we had the Bucket Brigade. This was a people-intensive process designed to deliver water from the nearest pump, pond or river with as little risk, delay and effort as possible. The principle of a bucket-brigade is that a chain of people forms between the pump and the fire and they pass buckets in two directions – full ones from the pump to the fire and empty ones from the fire back to the pump.
A bucket brigade is useful metaphor for many processes and an Improvement Science Practitioner (ISP) can learn a lot from exploring its behaviour.
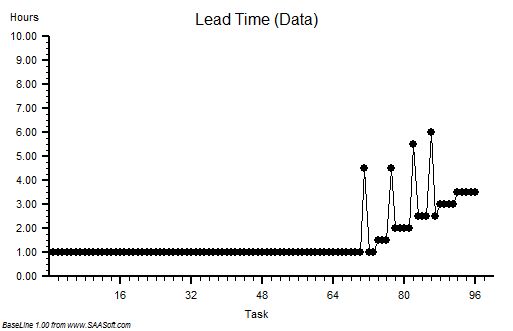
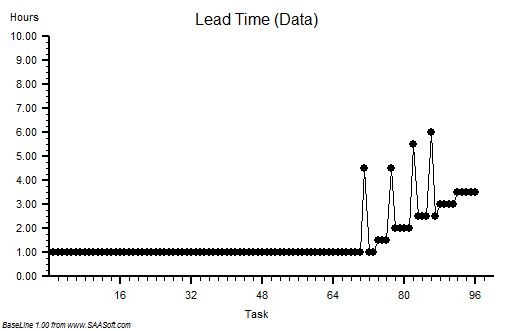
First of all the number of steps in the process or stream is fixed because it is determined by the distance between the pump and the fire. The time it takes for a Bucket Passer to pass a bucket to the next person is predictable too and it is this cycle-time that determines the rate at which a bucket will move along the line. The fixed step-number and fixed cycle-time implies that the time it takes for a bucket to pass from one end of the line to the other is fixed too. It does not matter if the bucket is empty, half empty or full – the delivery time per bucket is consistent from bucket to bucket. The outflow however is not fixed – it is determined by how full each bucket is when it reaches the end of the line: empty buckets means zero flow, full buckets means maximum flow.
This implies that the process is behaving like a time-trap because the delivery time and the delivery volume (i.e. flow) are independent. Having bigger buckets or fuller buckets makes no difference to the time it takes to traverse the line but it does influence the outflow.
Most systems have many processes that are structured just like a bucket brigade: each step in the process contributes to completing the task before handing the part-completed task on to the next step.
The four dimensions of improvement are Safety, Flow, Quality and Productivity and we can see that, if we are not dropping buckets, then the safety, flow and quality are fixed by the design of the process. So what can we do to improve productivity?
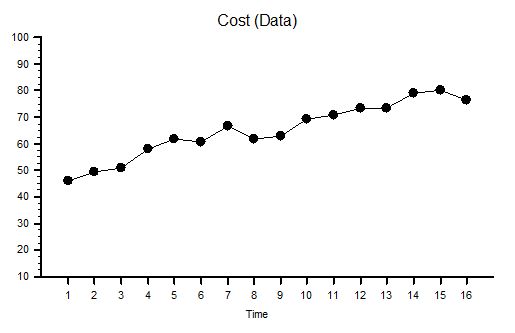
Well, it is evident that the time it takes to do the hand-off adds to the cycle-time of each step. So along comes the Fire Service Finance Department who sees time-as-money and they work out that the unit cost of each step of the process could be reduced by accumulating the jobs at each stage and then handing them off as a batch – because the time-is-money and the cost of the hand-off can now be shared across several buckets. They conclude that the unit cost for the steps will come down and productivity will go up – simple maths and intuitively obvious in theory – but does it actually work in reality?
Q1: Does it reduce the number of Bucket Passers? No. We need just as many as we did before. What we are doing is replacing the smaller buckets with bigger ones – and that will require capital investment. So when our Finance Department use the lower unit cost as justification then the bigger, more expensive buckets start to look like a good financial option – on paper. But looking at the wage bills we can see that they are the same as before so this raises a question: have the bigger buckets increased the flow or reduced the delivery time? We will need a tangible, positive and measurable improvement in productivity to justify our capital investment.
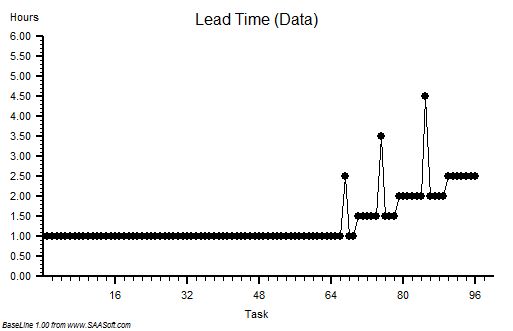
To summarise: we have the same number of Bucket Passers working at the same cycle time so there is no improvement in how long it takes for the water to reach the fire from the pump! The delivery time is unchanged. And using bigger buckets implies that the pump needs to be able to work faster to fill them in one cycle of the process – but to minimise cost when we created the Fire Service we bought a pump with just enough average flow capacity and it cannot be made to increase its flow. So, equipped with a bigger bucket the first Bucket Passer has to wait longer for their bigger bucket to be filled before passing it on down the line. This implies a longer cycle-time for the first step, and therefore also for every step in the chain. So the delivery-time will actually get longer and the flow will stay the same – on average. All we have appear to have achieved is a higher cost and longer delivery time – which is precisely the opposite of what we intended. Productivity has actually fallen!
In a state of near-panic the Fire Service Finance Department decide to measure the utilisation of the Bucket Passers and discover that it has fallen which must mean that they have become lazy! So a Push Policy is imposed to make them work faster – the Service cannot afford financial inducements – and threats cost nothing. The result is that in their haste to avoid penalties the bigger, fuller, heavier buckets get fumbled and some of the precious water is lost – so less reaches the fire. The yield of the process falls and now we have a more expensive, longer delivery time, lower flow process. Productivity has fallen even further and now the Bucket Passers and Accountants are at war. How much worse can it get?
Where did we go wrong?
We made an error of omission. We omitted to learn the basics of process design before attempting to improve the productivity of our time-trap dominated process! Our error of omission led us to confuse the step, stage, stream and system and we incorrectly used stage metrics (unit cost and utilisation) in an attempt to improve system performance (productivity). The outcome was the exact opposite of what we intended; a line of unhappy Bucket Passers; a frustrated Finance Department and an angry Customer whose house burned down because our Fire Service did not deliver enough water on time. Lose-Lose-Lose.
Q1: Is it possible to improve the productivity of a time-trap design?
Q1: Yes, it is.
Q2: How do we avoid making the same error?
A2: Follow the FISH .

































{kind=link}
{kind=link}
{kind=link}
{kind=link}