
 A question that is often asked by doctors in particular is “What is the difference between Research, Audit and Improvement Science?“.
A question that is often asked by doctors in particular is “What is the difference between Research, Audit and Improvement Science?“.
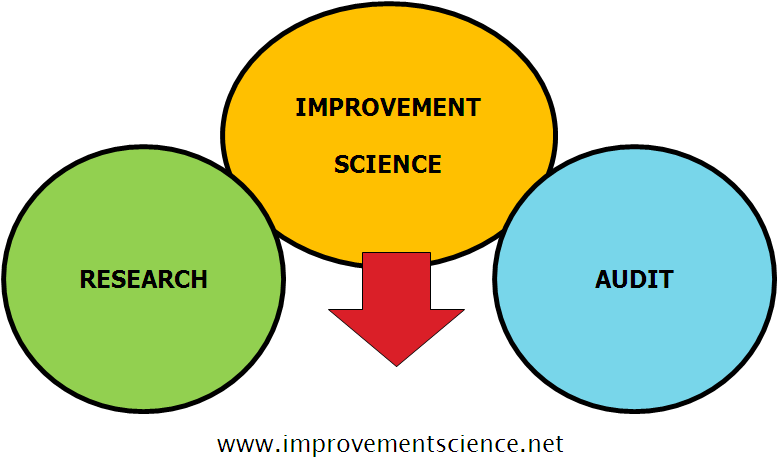
It is a very good question and the diagram captures the essence of the answer.
Improvement science is like a bridge between research and audit.
To understand why that is we first need to ask a different question “What are the purposes of research, improvement science and audit? What do they do?“
In a nutshell:
Research provides us with new knowledge and tells us what the right stuff is.
Improvement Science provides us with a way to design our system to do the right stuff.
Audit provides us with feedback and tells us if we are doing the right stuff right.
Research requires a suggestion and an experiment to test it. A suggestion might be “Drug X is better than drug Y at treating disease Z”, and the experiment might be a randomised controlled trial (RCT). The way this is done is that subjects with disease Z are randomly allocated to two groups, the control group and the study group. A measure of ‘better’ is devised and used in both groups. Then the study group is given drug X and the control group is given drug Y and the outcomes are compared. The randomisation is needed because there are always many sources of variation that we cannot control, and it also almost guarantees that there will be some difference between our two groups. So then we have to use sophisticated statistical data analysis to answer the question “Is there a statistically significant difference between the two groups? Is drug X actually better than drug Y?”
And research is often a complicated and expensive process because to do it well requires careful study design, a lot of discipline, and usually large study and control groups. It is an effective way to help us to know what the right stuff is but only in a generic sense.
Audit requires a standard to compare with and to know if what we are doing is acceptable, or not. There is no randomisation between groups but we still need a metric and we still need to measure what is happening in our local reality. We then compare our local experience with the global standard and, because variation is inevitable, we have to use statistical tools to help us perform that comparison.
And very often audit focuses on avoiding failure; in other words the standard is a ‘minimum acceptable standard‘ and as long as we are not failing it then that is regarded as OK. If we are shown to be failing then we are in trouble!
And very often the most sophisticated statistical tool used for audit is called an average. We measure our performance, we average it over a period of time (to remove the troublesome variation), and we compare our measured average with the minimum standard. And if it is below then we are in trouble and if it is above then we are not. We have no idea how reliable that conclusion is though because we discounted any variation.
A perfect example of this target-driven audit approach is the A&E 95% 4-hour performance target.
The 4-hours defines the metric we are using; the time interval between a patient arriving in A&E and them leaving. It is called a lead time metric. And it is easy to measure.
The 95% defined the minimum acceptable average number of people who are in A&E for less than 4-hours and it is usually aggregated over three months. And it is easy to measure.
So, if about 200 people arrive in a hospital A&E each day and we aggregate for 90 days that is about 18,000 people in total so the 95% 4-hour A&E target implies that we accept as OK for about 900 of them to be there for more than 4-hours.
Do the 900 agree? Do the other 17,100? Has anyone actually asked the patients what they would like?
The problem with this “avoiding failure” mindset is that it can never lead to excellence. It can only deliver just above the minimum acceptable. That is called mediocrity. It is perfectly possible for a hospital to deliver 100% on its A&E 4 hour target by designing its process to ensure every one of the 18,000 patients is there for exactly 3 hours and 59 minutes. It is called a time-trap design.
We can hit the target and miss the point.
And what is more the “4-hours” and the “95%” are completely arbitrary numbers … there is not a shred of research evidence to support them.
So just this one example illustrates the many problems created by having a gap between research and audit.
And that is why we need Improvement Science to help us to link them together.
We need improvement science to translate the global knowledge and apply it to deliver local improvement in whatever metrics we feel are most important. Safety metrics, flow metrics, quality metrics and productivity metrics. Simultaneously. To achieve system-wide excellence. For everyone, everywhere.
When we learn Improvement Science we learn to measure how well we are doing … we learn the power of measurement of success … and we learn to avoid averaging because we want to see the variation. And we still need a minimum acceptable standard because we want to exceed it 100% of the time. And we want continuous feedback on just how far above the minimum acceptable standard we are. We want to see how excellent we are, and we want to share that evidence and our confidence with our patients.
We want to agree a realistic expectation rather than paint a picture of the worst case scenario.
And when we learn Improvement Science we will see very clearly where to focus our improvement efforts.
Improvement Science is the bit in the middle.